 DigiMax
DigiMax本文作者:互联网数据官创始人和原创作者:宋星
竞价排名(SEM)对所有追求效果的营销人而言,都绝对是一个不能绕开的话题。
关键词、创意、质量分、着陆页等等,已经有一套非常成熟可循的方法,每个行业也有自己的套路。我不打算重复这些内容,因为我相信,100个人有100个SEM优化策略和方法,所以我得讲讲我的心得。
希望是大家都没有注意到的心得。
一、SEM分析常见的问题
分析SEM不同于自己做SEM。自己做,和去分析一个从来没有见过的账户,所处的位置不同,角度就不一样。
做SEM,是要自己做好,所以很注重细节。分析SEM,常常犯的第一个错误,是直接跳到细节里面去了。
SEM确实很琐碎,所以更不能直接陷入细节。
第二个容易出现的问题,是SEM太孤立了,只考虑SEM自己的事情。但SEM要做的好,反而跟SEM之外的东西特别相关。这些东西是什么,我们后面的内容会讲到。
这两个思维,高阶的SEM优化师应该都有体会。
好,不卖关子,我们由这两个问题出发,看看对于一个暂时还没有强大品牌的商品而言,它的SEM应该如何分析,从而如何优化。
二、3个传统的(旧)模型和它们的局限
为了快速分析SEM的表现,SEM有3个模型非常常用(但即使是这么常用的模型,其实很多SEM优化的朋友也不用,原因在于我们真的容易陷入细节)。
第一个模型:费用和转化的四象限模型
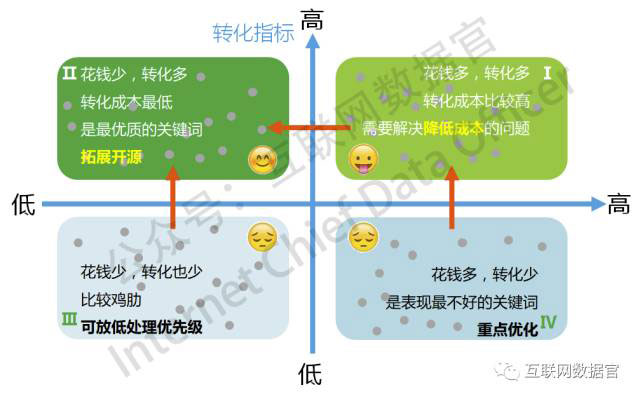
类似这种模型大家一定都看到过,这是互联网营销分析(其实也是所有的经营分析)中最常用到的模型。用于通过两个维度对事物进行区隔。在SEM关键词的宏观研究场景下,这是一个非常赞的模型。
这个模型的优点在于,非常易懂,对关键词表现的宏观把握有很大帮助。
缺点在于,这个模型本来是帮助你对宏观进行把握的,但是为了了解这四个象限背后到底发生了什么,你又不得不立即进入到微观的词的细节之中去。例如按照上面的四象限所做出的下面的具体的词的细分情况:
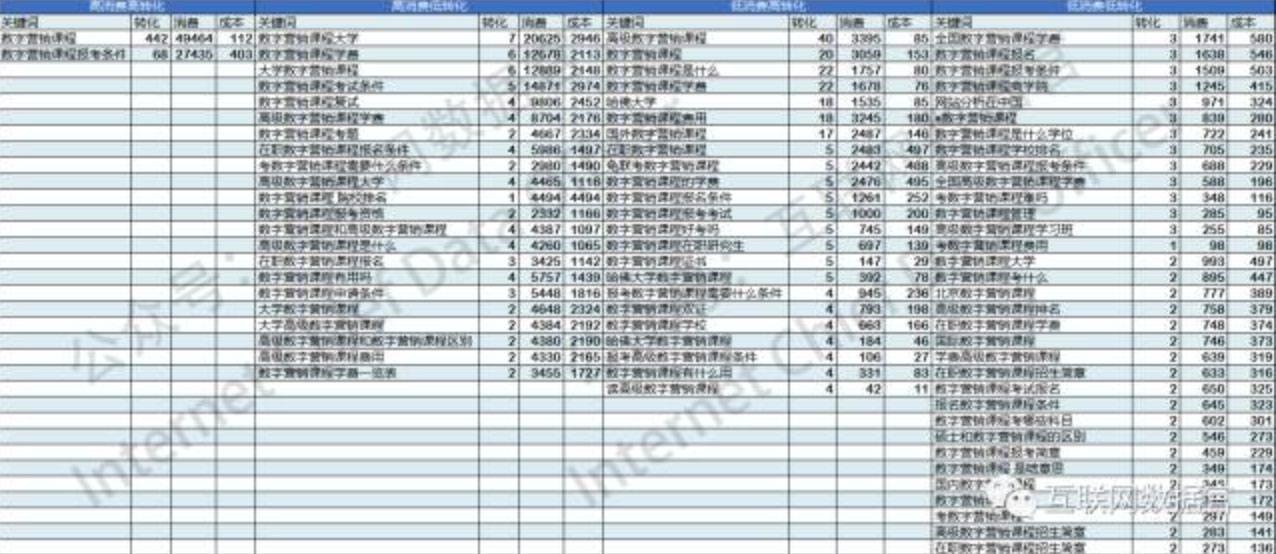
于是,你看到了很细节的很多关键词的情况,但你仍然不知道我应该如何着手优化这些词。因为,从每一个词自身的词义看,不同词之间有着本质的差异。有些词的词义就决定了它更容易转化(例如,品牌词、到哪里买、价格如何之类的词),而另一些词本身并不容易转化(通用词之类的)。因此,按照四象限模型的粗浅要求,对那些花费高的想办法降低费用,或者对那些转化低的想办法提高转化,或者对低花费高转化的词进行开源拓词等等,与其说是优化策略,不如说更多的是指导思想,而很难帮助你形成具体的行动。
所以,讲这个模型的人多,但展开来讲的估计你没见过。因为根本就没法展开。
第二个模型:长尾模型
长尾模型从词频分布的角度描述了一个SEM账户内的关键词分布状况。这世界上的SEM账户基本上都符合二八甚至一九分布规律。例如下面的这个账户内关键词的分布:
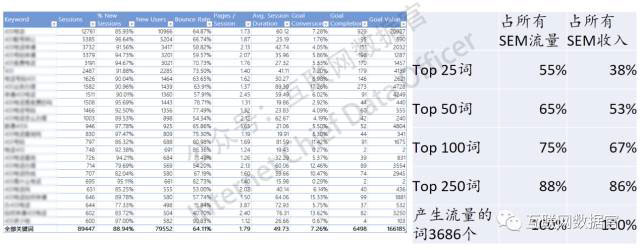
这个账户的前250个词(只占所有产生流量的词的6.8%)带来了88%的流量和86%的转化收入。比较典型。
另一个账户也非常体现出这种规律(如下图),所有产生流量的关键词中,只有头部的极小部分产生了显著的流量。
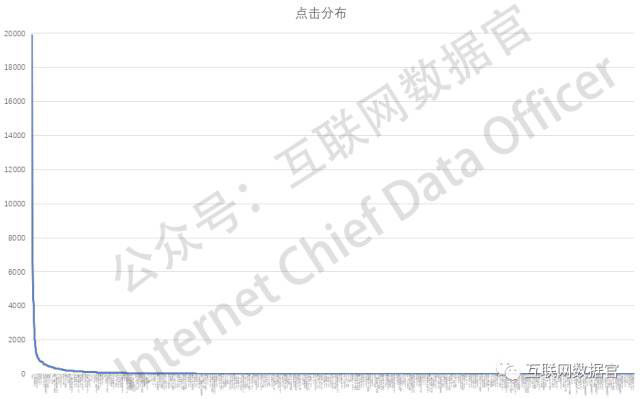
所以,利用这个模型,我们很愉快的能够接受一个结论:账户优化其实很容易,我们搞好这些最能带来流量的头部的词就OK了!
但是,在真正优化执行过程中,这个模型也几乎无法派上用场。最重要的问题在于,由于我们所选取的关键词都是核心词的延展,尾部词(这里讲的尾部词指流量少的词,而并非投放意义上的长尾词)中的很多词,其实跟头部词是完全一样的核心词,这些与头部词具有同样核心词的尾部词每一个虽然带来的流量很有限,但合并在一起,跟头部词相比,差异也不是特别巨大了(没有数量级的差异),这就让我们根本就不可以放弃对尾部词的分析和优化。
不过,问题在于这些尾部词数量太多,我们不可能一个一个进行具体的分析,我们需要对它们进行整体性的把握。
这个模型就鞭长莫及了。
第三个模型:转化漏斗
转化漏斗是最容易(尽管不是很容易能实现数据的准确)操作,但又最容易产生误导的模型。
我们会把整个SEM账户(或者账户的计划、单元等)按照“曝光 -> 点击 -> 流量 -> 咨询 -> 有效咨询 -> 注册 -> 购买”类似的过程来做每一个转化步骤,从而快速定位哪里出现了问题。
这个方法是每一个做SEM分析和优化的朋友必然会采用的方法。但从操作上看,它有两个主要问题(尽管并非是这个模型本身的问题)。
首先,转化漏斗模型需要全流程的精确数据,但这些数据很难全部准确的获取。尤其是对于需要一定转化周期的行业,例如金融、培训、医疗,消费者有相当长的决策周期。因此,我们能够比较实时统计的转化基本只能到“有效咨询”这个层级。这削弱了这个模型的价值。
其次,转化漏斗的形式是帮助我们强化过程观,但它本身却恰恰削弱了过程的细分。这听起来很矛盾,但并不难理解。能够被漏斗构建的过程,都是大过程,而无法包含用户更加细微的行为。但是,正是这些用户更细微的过程,反映了,甚至支配了转化的发生。一个极端但非常常见的例子是单页推广。转化漏斗在单页推广上几乎无法发挥作用。
因此,转化漏斗极为有价值,但是如同我在另外一篇文章《优化转化:除了转化漏斗,你的弹药库还需要几种分析武器》所写的那样,转化漏斗并不足以支撑全部的转化分析。
这三个模型都非常经典 ,但也都有局限性。我们不能因噎废食,忽略这几个模型,尤其是对于SEM而言,这几个模型都极有价值,但完全依靠这几个模型,还是太过宽泛,即使能够给我们一些好的线索,也无法帮我们解决实际落地的问题。
三、三个新模型
第一个新模型:相对ROI细分模型
“相对ROI”的原因,是为了弥补ROI无法准确统计到各个具体关键词的不足。
为什么ROI无法准确统计呢?最主要的原因有两个,其一,是很多SEM投放,最终的转化在线下完成,线上线下难以打通,实际发生的转化回溯不到最初投放的关键词上。现在所谓的利用DMP打通线上线下环节的,都不具有实用性。其二,很多SEM投放的转化,具有“时延性”,并不会在短时间内就发生转化,在统计的时候,时间范围选取的不同,转化的数目也不一样。因此ROI的计算,一定是模糊的,不可能精确。
这时候一个不错的替代方法是计算“相对ROI”。所谓“相对ROI”,是正常ROI不可取得情况下不得已而为之的替代,但却反而延伸出更具价值的分析。
为了说明相对ROI的概念,我们先引入另一个概念:“前导转化”。
前导转化并不是真正可计算金额的转化,而是将不可准确计算的最终转化,用可以当日获取的最靠后的转化替代。由于这些转化发生在最终产生收入之前,因此得名“前导”。
比如,对于教育行业,我无法立即计算出今天投放的竞价最终最终能获得多少的报名,但我可以把今天发生的有效询盘全部记下来,并且对应到相应的关键词。由于拉长时间线之后的有效询盘和最终转化有比较固定的比例,因此利用有效询盘作为替代性的“最终产出”仍然具有分析价值。
于是,我们的ROI计算就从:
投放费用 -> 最终收入
转变为:
投放费用 -> 当日最靠后的转化(如有效询盘)。
当然,讲到这里大家会说,这没有什么特别之处呀。请接着看。
基于前导转化计算出的每个关键词的“前导ROI”的数值(但并非是真正意义上以收入÷费用的ROI),然后进行纵向(时间趋势)或者横向(跟其他词)的比较是很有趣的。这个很简单,大家都会,我就不介绍了。这个方法的另一个常用场景是在帮助我们快速辨识各类词性对应的效果上,例如下面的例子:
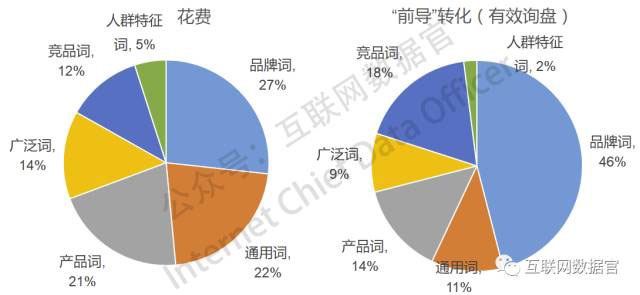
左边的饼图是各类词性的词所产生的投放费用的占比,右边的饼图则是各词性的词所产生的“前导”转化占所有前导转化总数的占比。
可以看出,品牌词花了27%的钱,但贡献了46%的转化。如果我们将这两个比例进行对比,可以得出一个比值:(46% ÷ 27%)= 1.70。这个值,是我们所讲的相对ROI(本质上仍然还是费效比)。
计算相对ROI很容易,不费吹灰之力,于是我们得到一个对比关系的表:
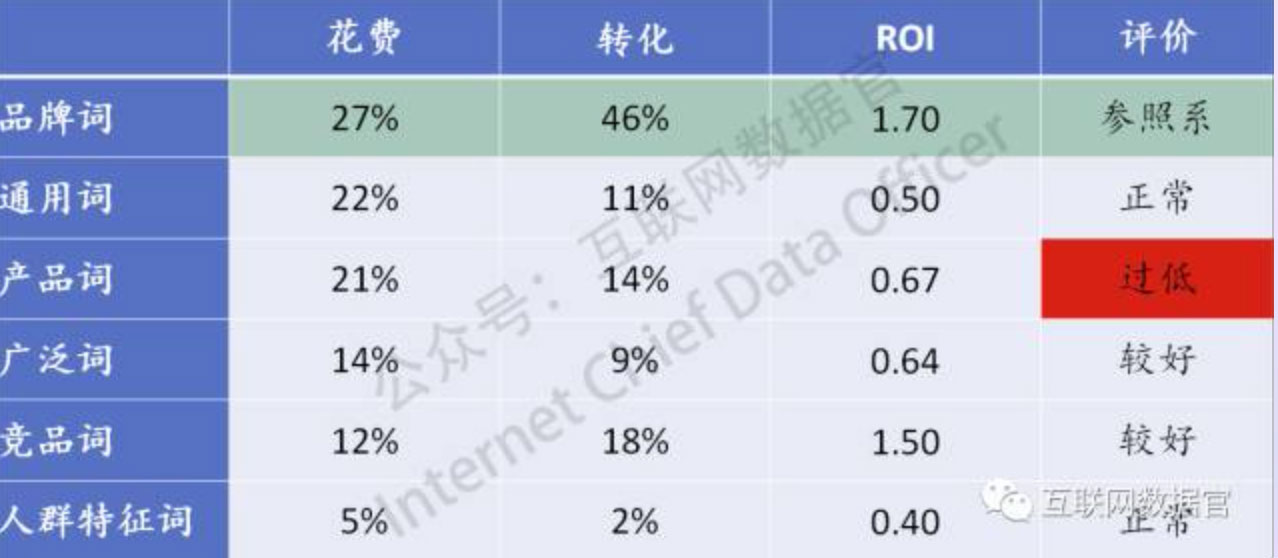
看到这个表,你肯定会明白,相对ROI最大的价值在于作为横向比较不同词性、不同关键词投放效率的工具。我们可以通过这个模型,极为快速的定位不同类别词性(或者具体的词)的表现的高低。在上图中,产品词比竞品词的表现如果差很多,甚至堕落到跟广泛词通用词相当水平的话,说明了很多种可能性:产品本身的影响力匮乏?产品介绍的吸引力较弱?(——因为竞品词表现好,或者说明人们被暗示这个商品和竞品一样甚至有更好的品质,所以反而增加了转化),又或者是产品词的创意本身就存在重大问题?总之,通过这个分析,你发现了问题,有了好的改善的额目标。
在下半部分文章中,我将用一个具体的(脱敏的)案例,继续向大家介绍另外两个新的模型,以及会把原始数据提供给大家。请大家follow我们的公众号,继续对我们保持关注。谢谢!