 DigiMax
DigiMax微博是很多人最常使用的社交平台。吐槽、追星、发自拍、看视频、开直播等,如今微博的内容和互动形式越来越多元化。由此累积下来的庞大数据和复杂的用户互动场景,也让人工智能在微博有了用武之地。微博团队是如何玩转人工智能的?如何对明星进行图像识别?
用AI来分析内容已成微博“刚需”
今天我想跟各位分享的是人工智能在微博中的应用。
从背景上看,微博之所以要做人工智能,很大程度上和微博内容形式的变化有关。随着智能终端设备、技术的发展,音视频和图像成为用户发微博的主要内容形式之一,并且在微博总发博量中占的比例越来越大。目前,微博的日活跃用户(DAU)达到1.65亿,月活跃用户(MAU)达到3.76亿。在月活用户之中,移动端月活占比达到92%。这些用户越来越喜欢发布图文、视频,其中,微博目前的直播总场次已经达到了8700万,博文数量达到2600亿条。
有了海量内容和用户,我们很想知道用户和内容之间的关联是什么,用户和用户之间的互动关系体现在哪里。
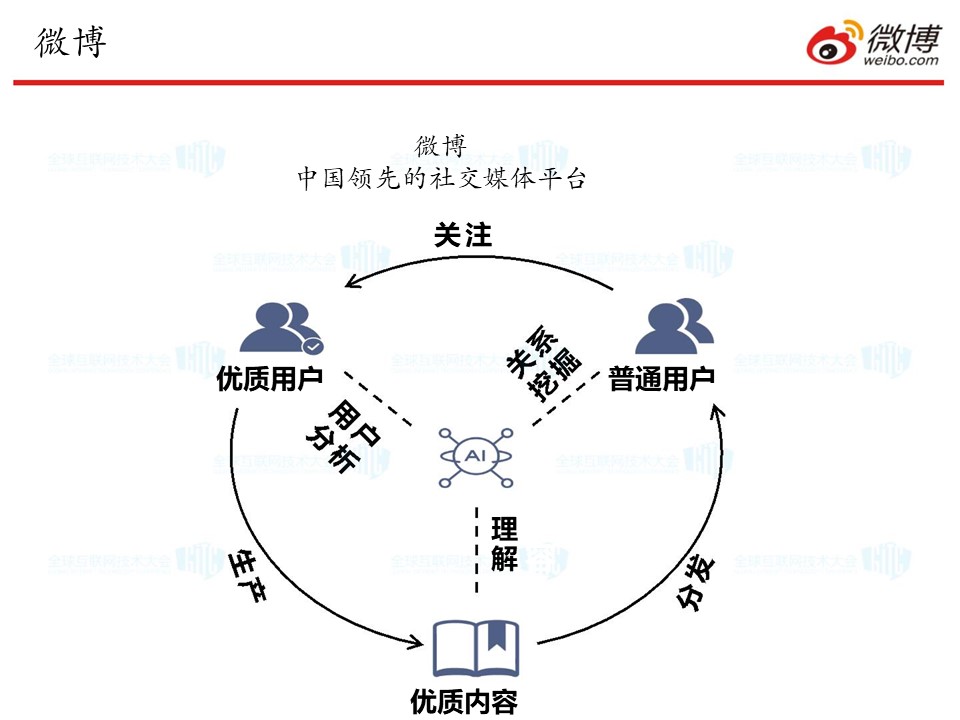
(图片说明:AI在微博用户和内容中的应用结构图)
应当说,利用AI精准分析图像视频已经是微博的“刚需”。并且近年来由于计算机硬件的发展,特别是GPU的发展,为人工智能算法的广泛应用提供了一个坚实的基础。
今天我将介绍微博的三个典型的人工智能应用场景:图像识别、视频重复性检测以及明星识别。看看我们是如何将人工智能技术用于用户分析、内容理解、用户关系挖掘以及内容推荐。
微博AI典型应用场景一:图像标签
首先我们看一下给图像打标签。
我们先看下边的例子。这些都是用户发的一些优质微博,但我们没有对这些内容打上标签。
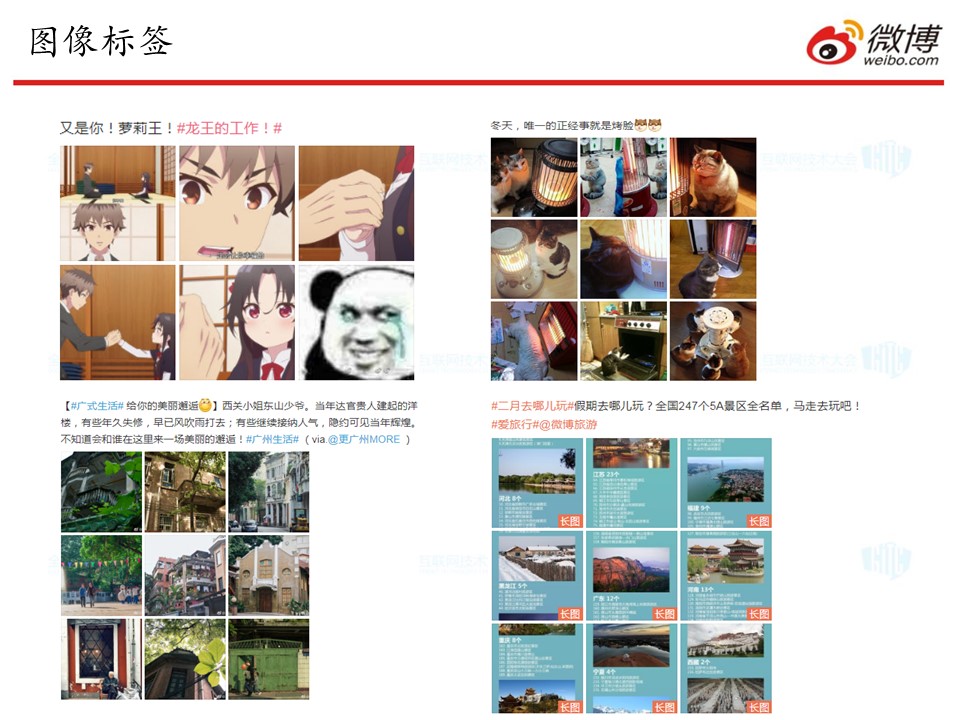
所谓打标签,指的是用一些关键词来描述微博的内容,从而体现出用户的兴趣、能力等。微博有一套自己的标签体系,它可以刻画用户的兴趣、描述微博的内容。
在微博中,“标签”是连接用户兴趣和微博内容的纽带。对图像打上标签,是理解微博内容的基础。基于这样的基础,我们可以把打上标签的微博实时推送给用户,由用户来消费这些微博的内容,进而产生用户互动。
可以再看下面的一个例子:

可以看到,这4条微博的内容形式都是文本内容很短,但是图片很丰富。这在微博中算是优质的内容,那么我们就有必要为其打上标签。
下面我介绍一些我们给图像打标签的算法。我们可以先设想这样一个场景,比如我们对这些微博打上了标签,然后我们会把这些标签建立索引,接着根据用户的兴趣、用户的点击历史等一些因素,进行粗召回、排序,最终输出为给用户消费的内容。

在算法上,我们采用的一种业界公认效果最好的算法模型Inception-ResNet-v2。这是一种有监督的方法,指的是在有了一定量的标注数据的基础上,通过模型去训练这些标注数据,学习出它们内在的一种规律性。然后给新的未知的图像内容打上标签。
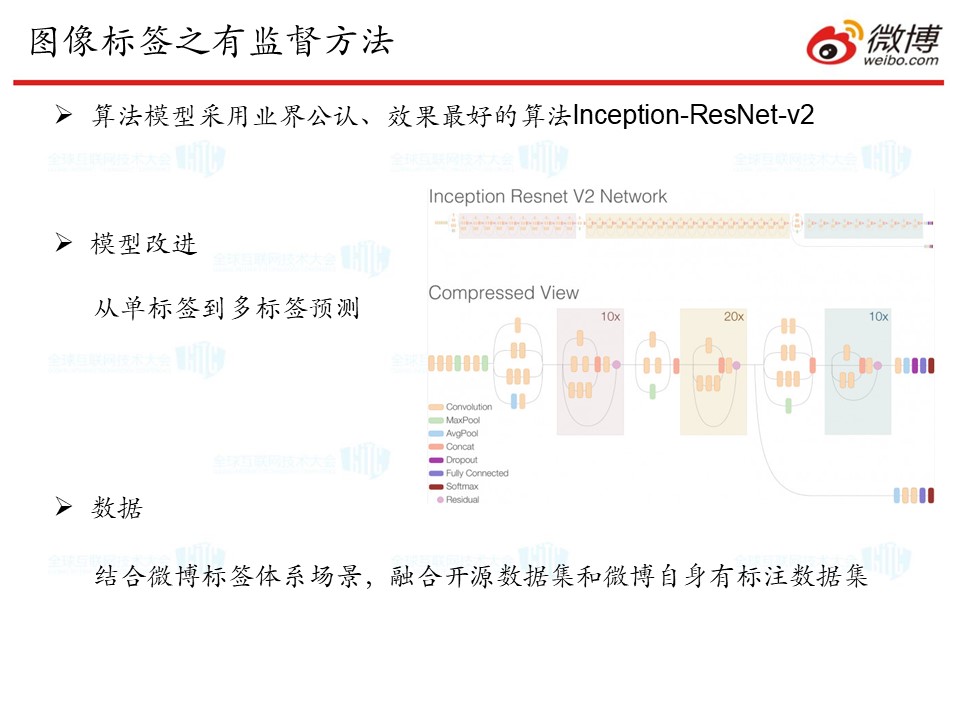
我们对这个模型算法进行了改进,使它可以从预测单标签,到目前可以预测多标签。至于模型训练中用到的数据,我们用的是开源数据集的数据,以及我们微博自己的图像标注数据集。
除此之外,我们在给图片打标签时,也用到了其他一些算法,比如多模态方法。
所谓多模态,指的是融合微博中的文本、图像、视频、音频等内容的几种方法,为这类形式更多元的微博打上标签。因为有时候,因图片的信息量较少,不足以预测其内容,就需要结合文本语义等其他内容来打标签。在这个过程中,我们使用了fine tune ResNet方法。
可以来看下我们打标签的效果(图中蓝色字样为机器所打的标签):
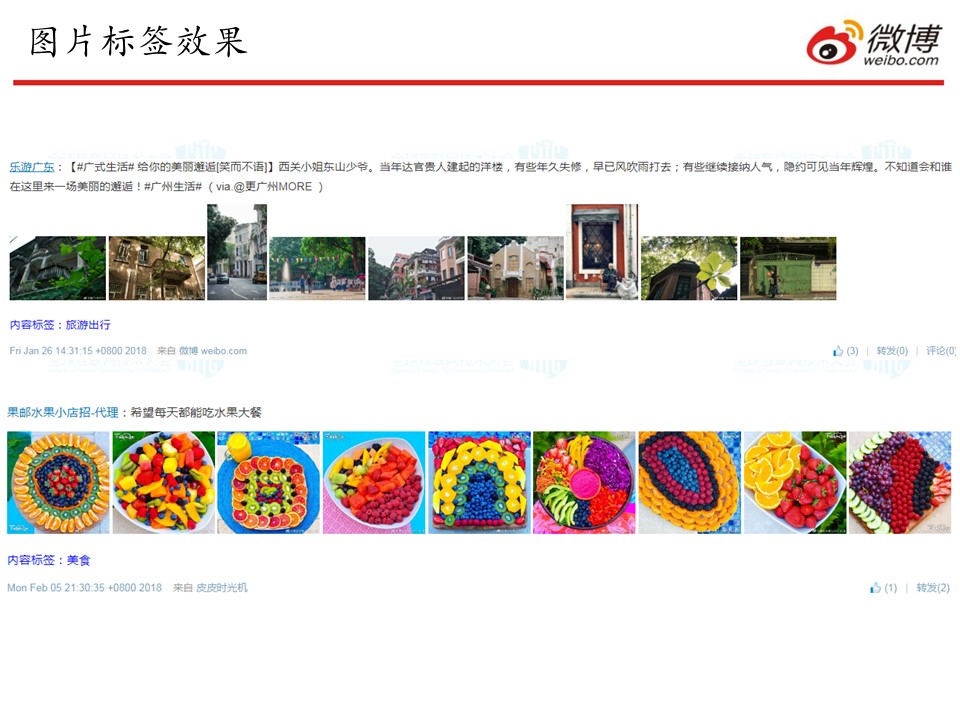
可以看到,上面这则微博发了很多图片,然后配了较少的文字,但这些文字不足以说明这则微博属于旅游出行方面的内容。这时候就需要结合图像信息来打标签。像是旅游建筑的图片,我们就打上了旅游出行方面的标签。而像是各种果蔬的图片内容,我们就会打上美食的标签。总体上,我们给图片打标签的效果还是非常好的。
微博AI典型应用场景二:视频重复性检测
第二个例子是视频重复性检测。
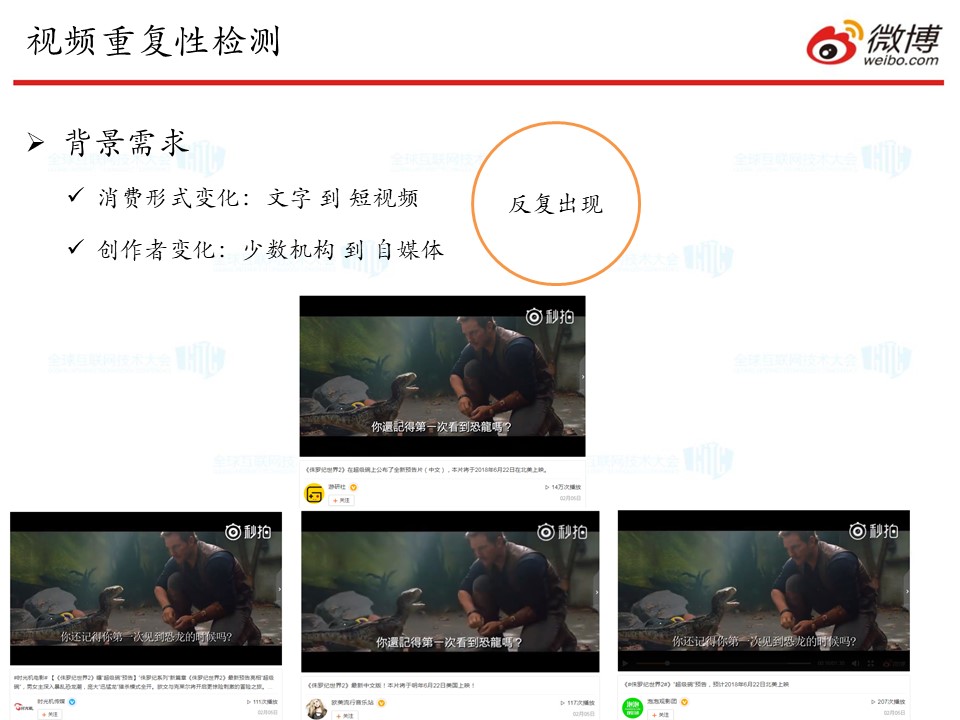
这一应用场景主要也是缘于发微博形式的变化。随着内容从文字逐步走向短视频等多媒体形式,同一个视频可能会被重复发布很多次,这背后甚至可能涉及到版权方面的问题。
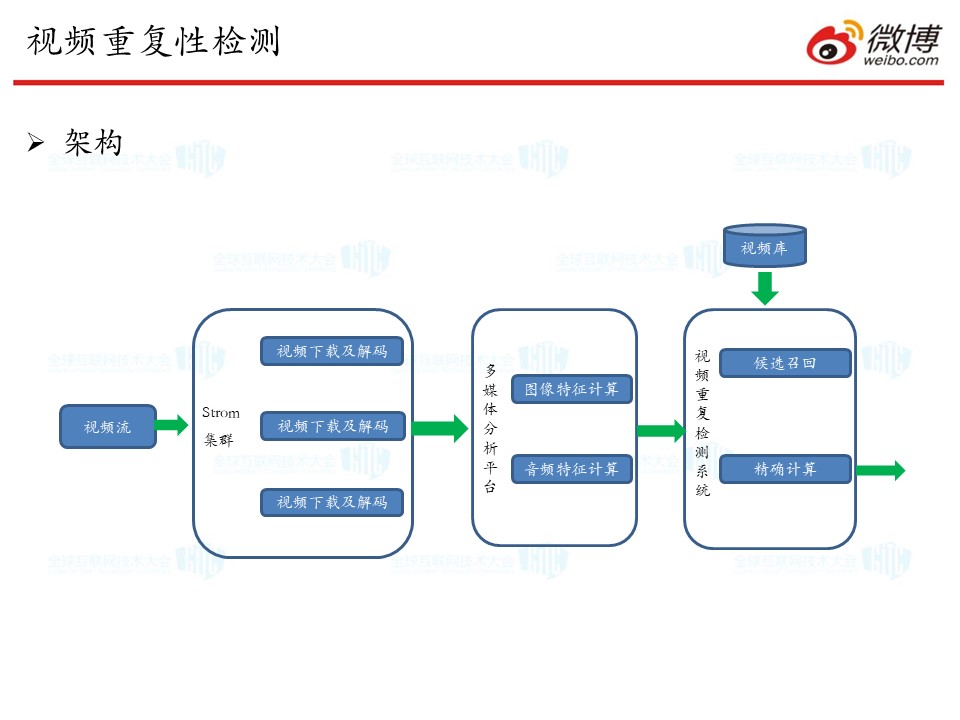
我们为此重新设计了系统架构(如下图所示)。当微博用户一发视频,我们就可以用Strom集群把视频下载下来进行解码,然后通过我们的多媒体分析平台进行分析,针对图像特征、音频特征等进行计算,最后送入我们的视频重复性检测系统。根据我们已有的视频库,可以发现视频的内容是否重复。
上述步骤中的重要一步是计算图像的特征,并进行对比。要做到这一点,我们采取了诸如抽帧(包括等间隔、等帧数)等方法。
等间隔抽帧,指的是按照固定的时间进行抽取,将视频中的图像抽取出来;而等帧数抽取,指的是每次固定抽取某个帧数,再进行对比。我们目前采用的是等间隔的与最大帧数相结合的抽帧方法。
在图像的特征计算环节,我们的算法没有使用连续多帧图像对。我们的需求是能够快速计算每帧图像,并且支持图像里边的旋转裁剪等变换,最后一定要保证候选的召回率高。
而在音频特征及比对算法上,我们使用的是基于音频的频谱特征的分析方法。这其中当然也和视频一样,涉及到抽帧。但音频不如视频的信息含量大,在一段时间内的信息量相对较少。因此我们采取了连续抽帧法,从而确保音频信息的丰富性。
下图展示的是我们音频频谱分析方法的过程:

我们可以看右上角的两个波形图表。第一个波形,是我们平常听到的声音的原始信号。第二个波形图就是经过了“加窗”处理之后的情形。这么做是为了确保信息的丰富性和连续性。
而在图的最左侧,我们通过把语音信号进行傅里叶变换,分析了音频的频域。这么做就为下一步快速比对两段音频的相似度打下了基础。
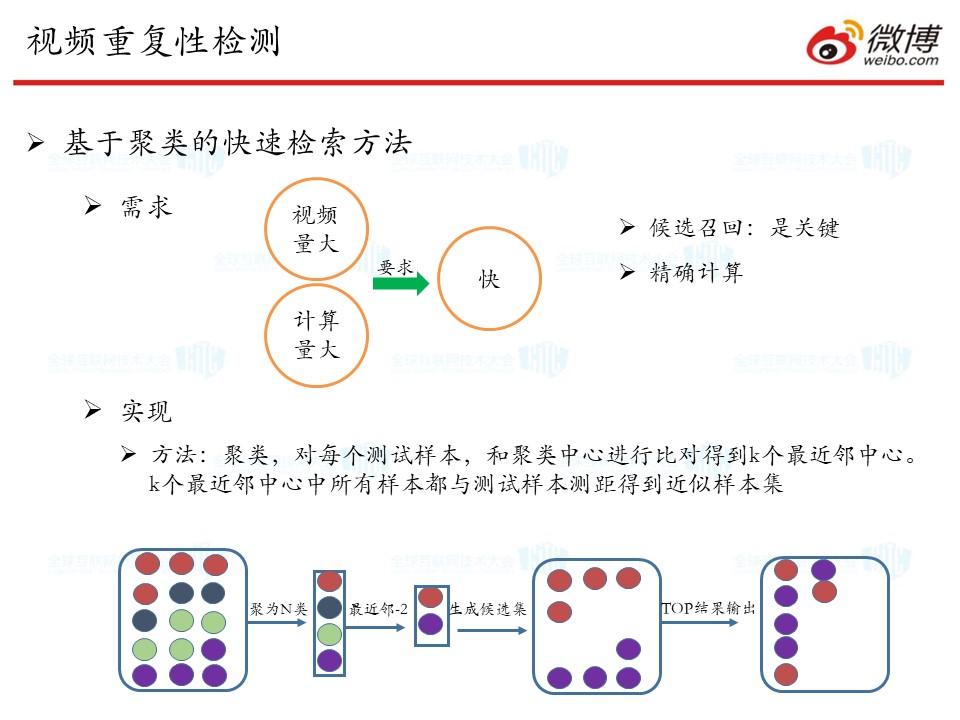
在最后的比对环节,还涉及到一个快速检索系统。要在用户发出微博的时候,就能快速分辨出和视频库中的视频的相似度,我们使用了改进的聚类方法。我们对音视频库里边的音视频经过计算特征之后,对其进行聚类,聚为N类。然后根据每个测试样本和聚类中心的距离,得到其最近的“近邻中心”,其后生成候选集并输出结果。
微博AI典型应用场景三:明星识别
最后我们再看一下,第三个应用场景案例——明星识别。
大家都知道微博的用户中有不少是明星,明星和粉丝的互动是微博用户互动的一个重要形式之一。明星的影响力通过粉丝进行传播,因此非常有必要对明星粉丝用户的发博内容进行图像识别,通过细化的标签内容来精准描述用户的兴趣。
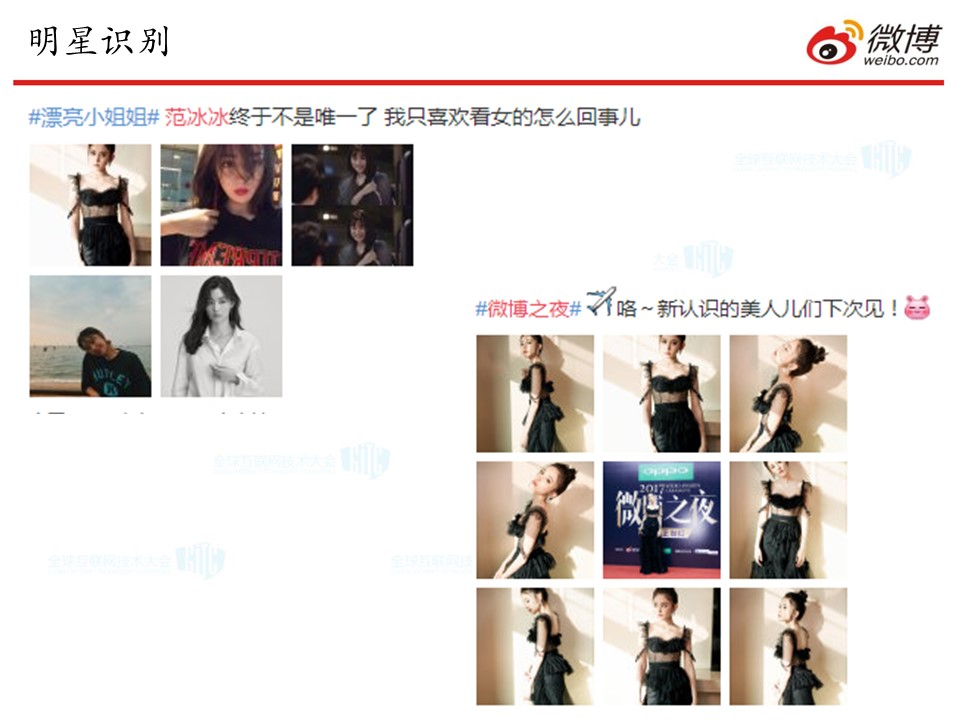
可以看下面两张图片:

第一张图,从图片内容来看,这名用户主要关注的是TFBOYS里面的王源。而右边这张图片虽然没有用文字明确说是杨幂,但从图片的特征来看,已经表明了就是杨幂。
再看另外两条微博:
从文本中看,微博中并没有提到迪丽热巴这个名字,但是反而提到了范冰冰。但实际上,内容主要注重的是迪丽热巴。
要进行明星识别,我们主要用的是SpereFace这个算法。这一算法最大的特色有两点,一是权值的归一化,二是角度间隔的极值化(可见下图)。
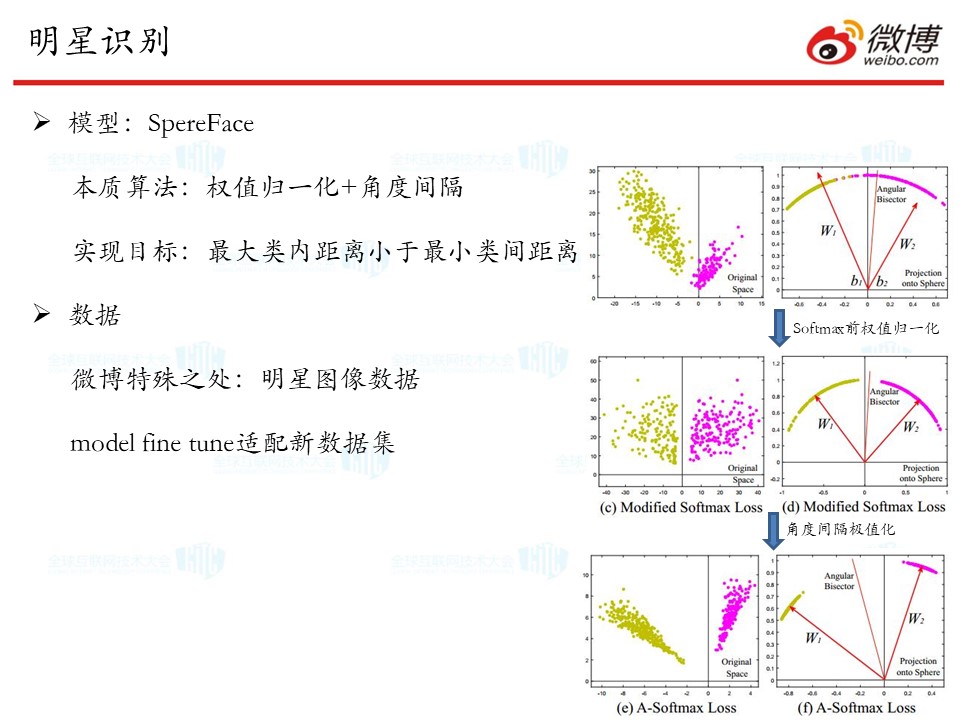
在数据方面,我们使用了微博特有的明星图像数据,并且对上述算法模型进行了微调,以适应我们自己的数据集。
下面是明星识别的效果展示,可以看到,对明星胡歌的不同照片的识别还是非常准确的。

上面是我分享的微博的三个典型的人工智能应用场景,除此之外,还有一些其他的应用:比如主feed排序、短文内容理解、图片的智能裁剪等。
微博有庞大的数据和海量的用户,复杂的场景正是微博的核心价值所在。不仅如此,我们的标注团队也为我们不断贡献标注的语料。我认为,通过人机结合、大数据闭环,能够让人工智能再往前走到超级智能,这是我们看到的未来,也是微博的使命。
(注:以上内容根据杨士新在数据侠线上实验室的演讲实录整理。图片来自其现场PPT,已经本人审阅。本文仅为作者观点,不代表DT财经立场。题图来源:视觉中国)
本文作者杨士新,微博机器学习团队资深算法工程师。
iCDO通讯员简介
童心,乐于学习和分享的数据从业者一枚。